
Redis最佳实践
1.键值设计
优雅的key结构
key的最佳实践约定
1.遵循基本格式:**[业务名称]:[数据名]:[id]**
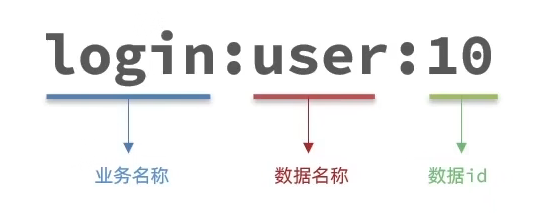
2.长度不超过44字节
3.不包含特殊字符
优点
- 可读性强
- 避免key冲突
- 方便管理
- 更节省内存:key是string类型,底层编码包含int,embstr和raw三种。embstr在小于44字节使用,采用连续内存空间,内存占用更小。raw模式下,内存空间不是连续的,而是会采用指针形式指向其他空间。
拒绝BigKey
什么是BigKey
- key本身的数据量过大,比如一个key的值就占了5MB。
- key中的成员数过多,比如一个ZSET类型的key,它的成员数量为10000个。
- key中成员的数据量过大,比如一个Hash类型的key,它的成员数量虽然只有1000个,但这些value的总大小为100MB。
推荐值:
- 单个key的value小于10kb
- 对于集合类型的key,建议元素数量小于1000

选择合理的数据结构

2.批处理优化
单个命令的执行流程
一次命令响应时间=一次往返的网络传输所耗的时间 + 1次redis执行命令耗时
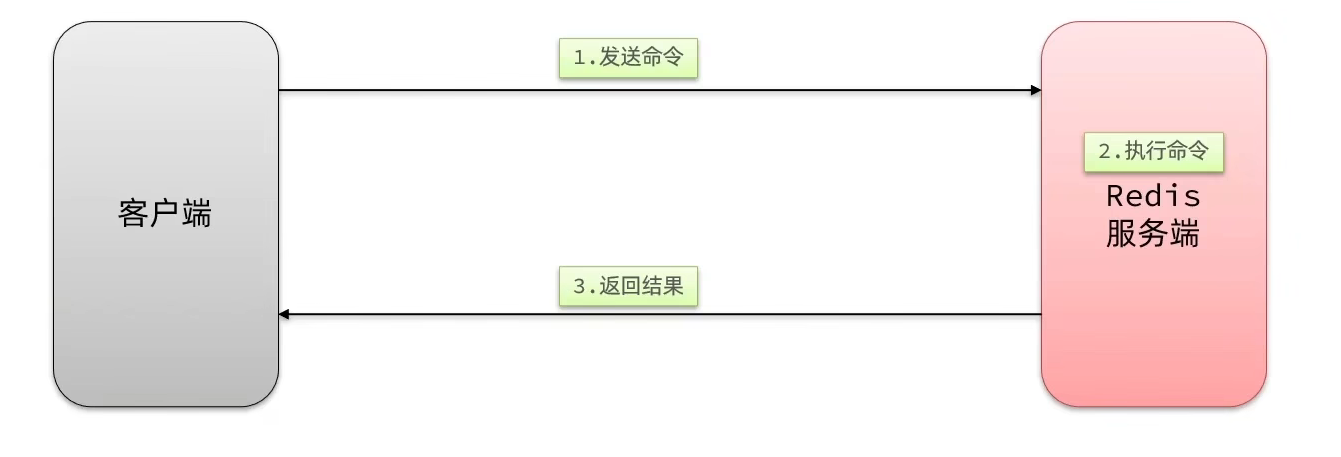
问题:一次命令响应时间耗费时长主要由网络传输耗时造成。这样导致N次命令的响应时间=N次往返的网络传输耗时+N次redis执行命令耗时。
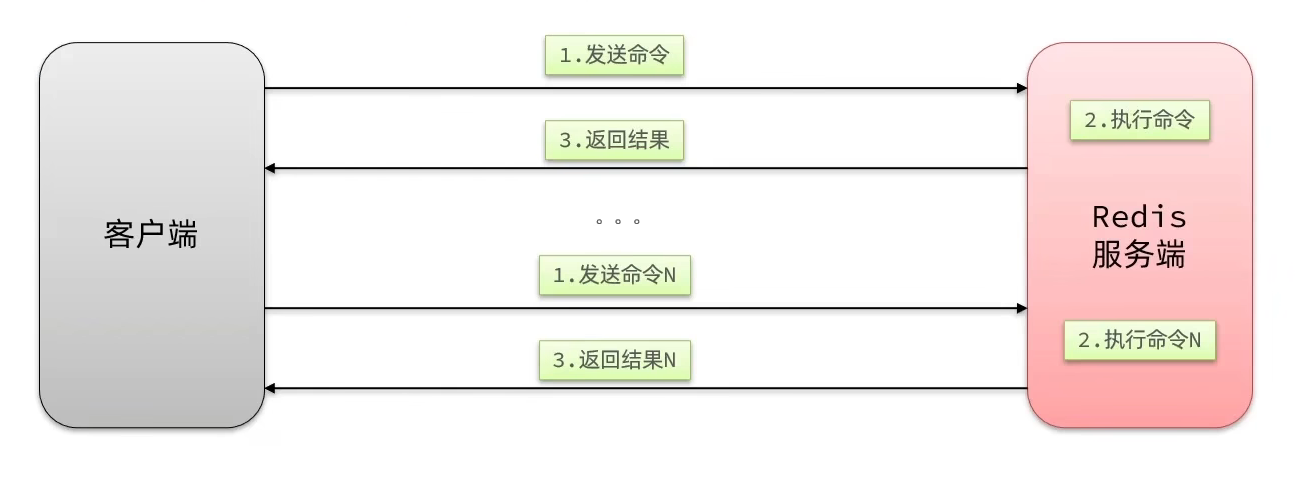
如果我们在处理某个业务流程时,需要多次循环往redis中存取数据时,会相当耗时,所以我们可以视情况而优化流程。比如使用MSET和Pipeline,来一次性通过网络发送全部的数据,而不是一次一次的发送。这就是批处理。
MSET
Redis提供了很多Mxxx这样的命令,可以实现批量插入数据。例如
- mset
- hmset
代码演示:
1 |
注意:不要在一次批处理中传输太多命令,否则单次命令占用的带宽太多,会导致网络阻塞
Pipeline
MSET虽然可以批处理,但是却只能操作部分数据类型,因此如果有对复杂数据类型的批处理时,建议使用Pipeline功能。
代码演示:
1 |
注意:Mxxx方法执行时间比Pipeline要快。因为Mxxx方法是redis原生的命令,是有原子性的,而Pipeline则是非原子性执行命令的,所以执行所有的命令期间可能会插入其他请求发送过来的命令,导致耗时慢些,不过问题不大。
集群下的批处理
集群处理暂时先不总结了。
总结
批处理方案
- 原生的M操作
- Pipeline批处理
注意事项
- 批处理时不建议一次携带太多命令
- Pipeline的多个命令之间不具备原子性
服务端优化
持久化配置
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Journey!