一、快速入门 普通maven项目 1.创建maven工程 2.引入依赖 1 2 3 4 5 6 <dependency > <groupId > dev.langchain4j</groupId > <artifactId > langchain4j-open-ai</artifactId > <version > 1.0.1</version > </dependency >
3.构建聊天对象OpenAiChatModel 因为Deepseek使用与OpenAi兼容的API格式,所以这里我创建了连接DeepSeek的模型
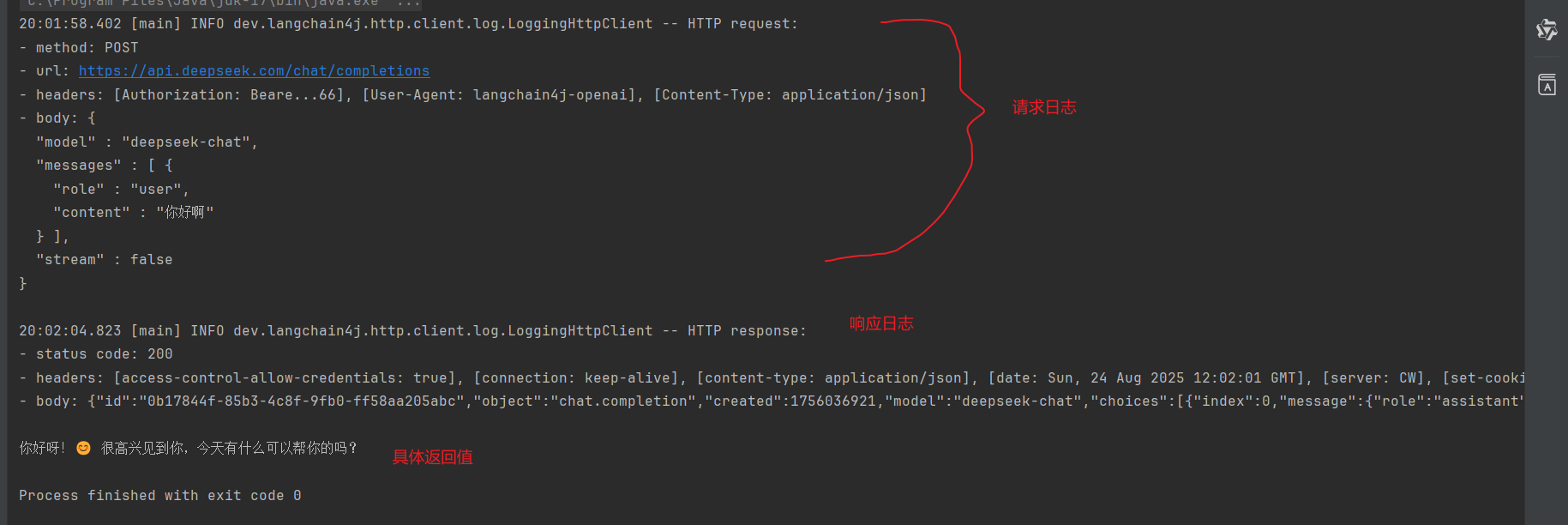
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public class App { public static void main (String[] args) { OpenAiChatModel model = OpenAiChatModel.builder() .baseUrl("https://api.deepseek.com" ) .modelName("deepseek-chat" ) .apiKey("" ) .logRequests(true ) .logResponses(true ) .build(); String res = model.chat("你好啊" ); System.out.println(res); } }
测试结果
Spring整合Langchain4j springboot项目创建看之前的博客。
1.核心依赖 1 2 3 4 5 6 <dependency > <groupId > dev.langchain4j</groupId > <artifactId > langchain4j-open-ai-spring-boot-starter</artifactId > <version > 1.0.1-beta6</version > </dependency >
2.在配置文件中配置大模型信息 1 2 3 4 5 6 7 8 9 10 11 12 13 14 langchain4j: open-ai: chat-model: base-url: https://api.deepseek.com model-name: deepseek-chat api-key: 自己的apikey log-requests: true log-responses: true streaming-chat-model: base-url: https://api.deepseek.com model-name: deepseek-chat api-key: 自己的apikey log-requests: true log-responses: true
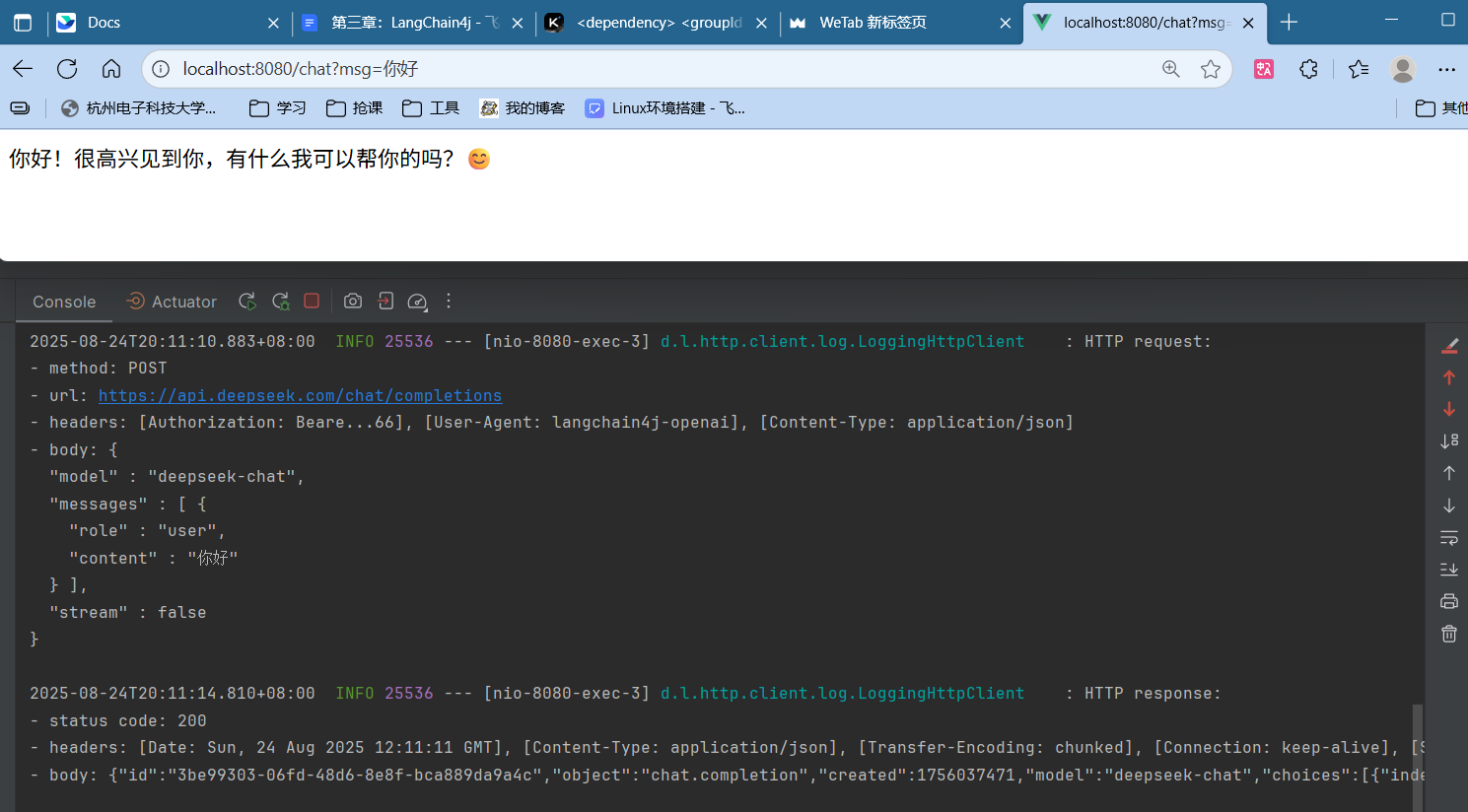
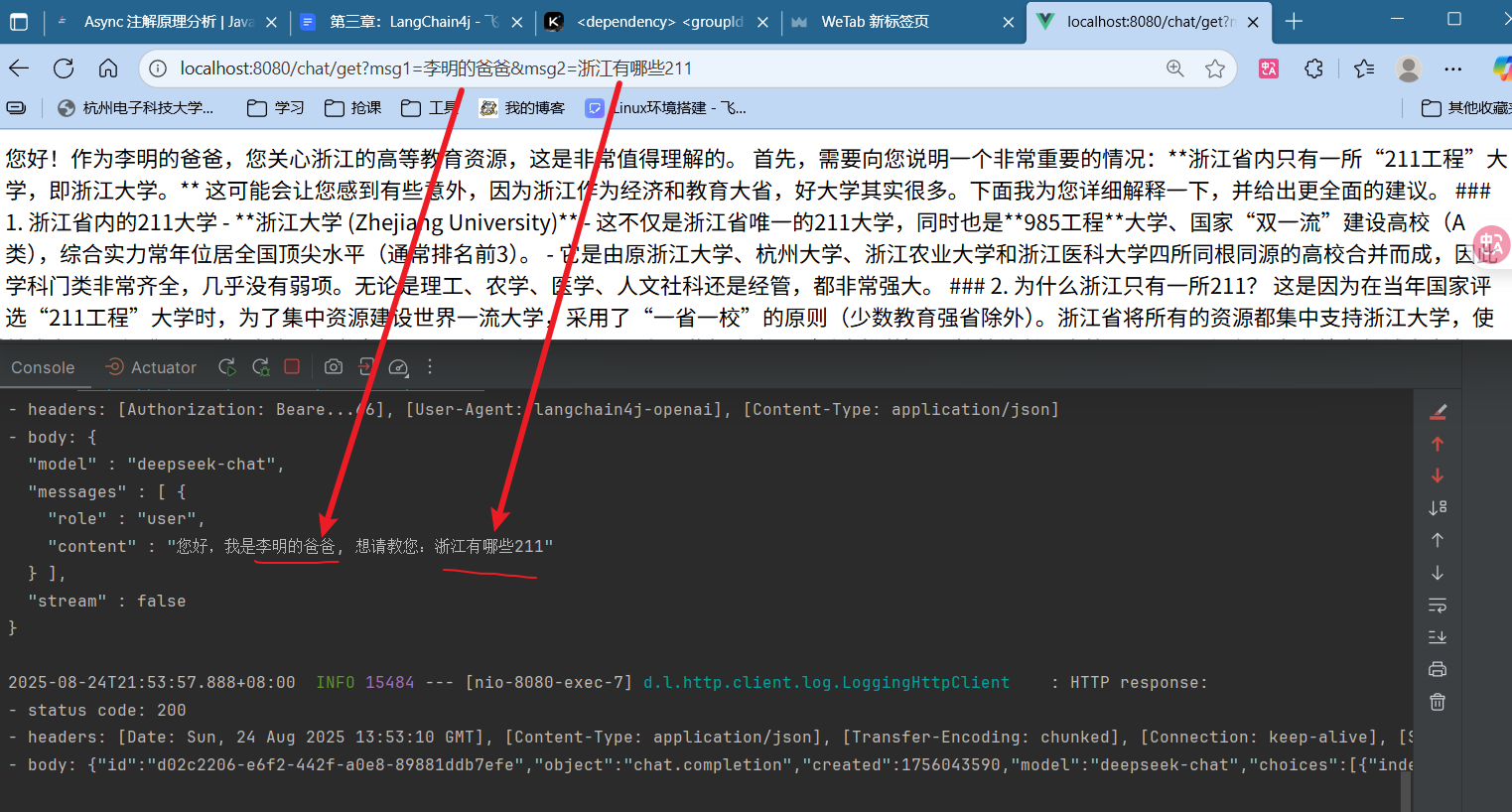
3.创建Controller调用接口 1 2 3 4 5 6 7 8 9 10 11 12 @RestController @RequestMapping("chat") public class ChatController { @Autowired OpenAiChatModel chatModel; @GetMapping public String get (String msg) { String chat = chatModel.chat(msg); return chat; } }
测试结果
综上,最简单的与大模型的交互就完成了。
二、进阶篇 1.AiService工具类 LangChain4j提供的工具类AiServices,是一个非常宝藏的工具。在快速入门中,访问大模型是借助于OpenAiChatModel的chat方法完成的。其实这种方式在实际开发中并不是很常用,因为如果使用这种方式调用大模型,将来我们完成一些高阶的功能,比如会话记忆/RAG知识库/Tools工具 的时候,在调用chat方法访问大模型前,我们需要自己做很多很多的工作,完成起来是比较复杂的。
为了简化使用,Langchain4j提供了AiService工具类,封装了有关model对象和其他一些功能的操作。这里以spring集成langchain4j为例来介绍。
基本使用 引入依赖 1 2 3 4 5 6 <dependency > <groupId > dev.langchain4j</groupId > <artifactId > langchain4j-spring-boot-starter</artifactId > <version > 1.0.1-beta6</version > </dependency >
声明用于封装聊天方法的接口 1 2 3 4 public interface ChatService { public String chat (String message) ; }
使用AiService工具类创建接口的动态代理对象 1 2 3 4 5 6 7 8 9 10 11 @Configuration public class CommonConfig { @Autowired OpenAiChatModel model; @Bean public ChatService chatService () { return AiServices.builder(ChatService.class) .chatModel(model) .build(); } }
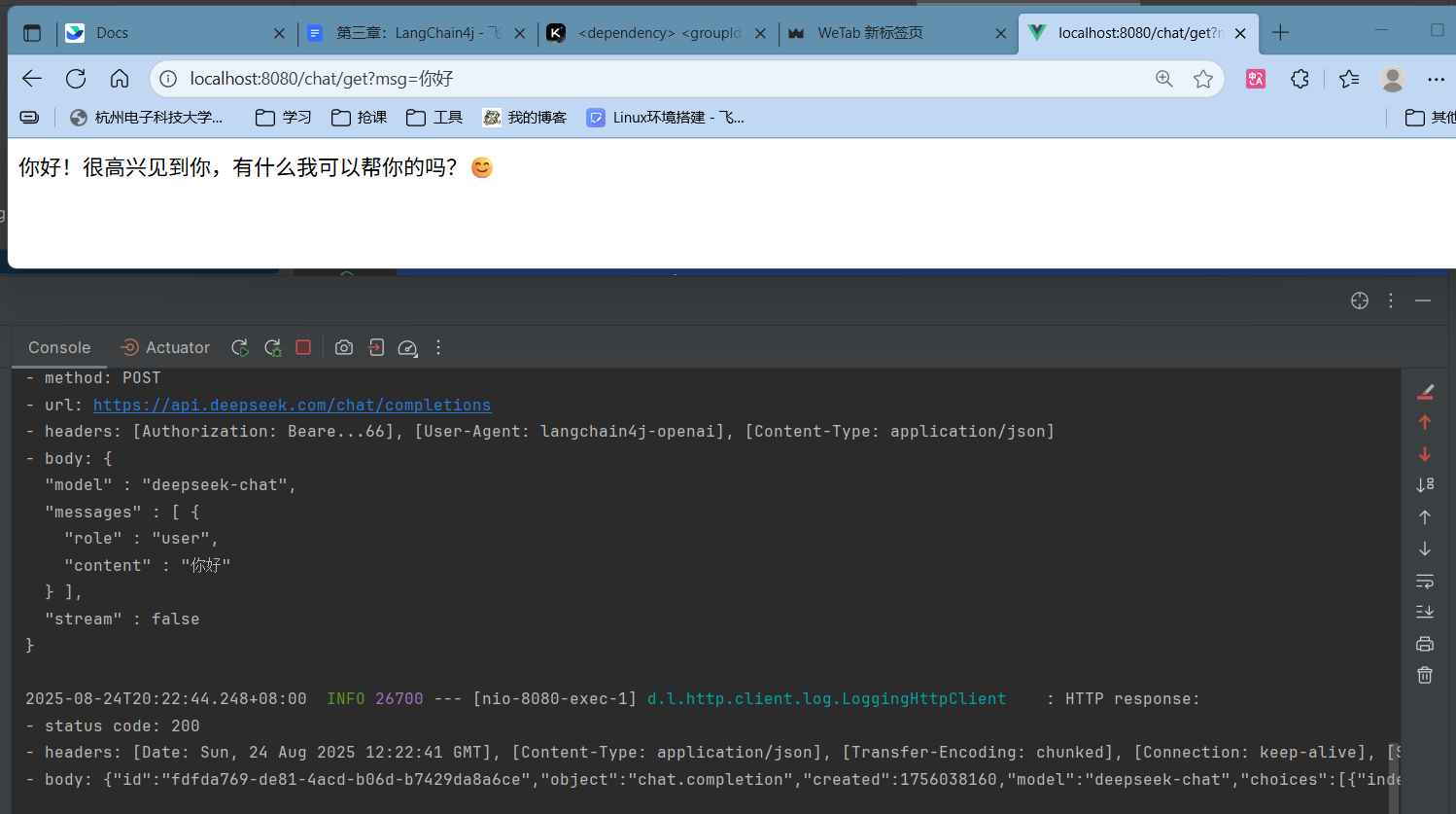
注入Controller并使用 1 2 3 4 5 6 7 8 9 10 11 @RestController @RequestMapping("chat") public class ChatController { @Autowired ChatService chatService; @GetMapping("/get") public String getChat (String msg) { String chat = chatService.chat(msg); return chat; } }
测试结果
原理介绍 当调用chatService.chat(msg)时,实际发生的过程是:
Java动态代理拦截了这个方法调用
Langchain4j将方法名和参数转换为对AI模型的请求
根据配置,向DeepSeek API发送HTTP请求
接收并处理AI模型的响应
将响应结果作为方法返回值返回
这种设计的优势在于,开发者只需要定义接口和方法,而不需要编写具体的实现代码,大大简化了与AI模型交互的复杂性。Langchain4j负责处理所有底层细节,包括HTTP通信、JSON序列化/反序列化、错误处理等。
在单个参数的情况下,默认给大模型发送的是用户信息,如果是多个参数,则需要通过注解指定各个参数的作用 。
声明式使用 为了简化AIServices工具类的使用,LangChain4j提供了声明式使用方法,想为哪个接口创建代理对象,只需要在该接口上添加@AiService注解并指定要使用的模型,将来LangChain4j扫描到该注解后会自动的创建该接口的代理对象并注入到IOC容器中,这样子就不需要我们手动在配置类中创建Bean对象了。接下来修改ConsultantService中的代码,并重新测试。
接口配置 1 2 3 4 5 6 7 8 @AiService( wiringMode = AiServiceWiringMode.EXPLICIT, //装配模式,手动 chatModel = "openAiChatModel" //要使用的模型在容器中的bean名称 ) public interface ChatService { public String chat (String message) ; }
在Langchain4j中,@AiService注解的wiringMode参数用于指定AI服务组件的装配模式。它有两个可选值:
1.AUTOMATIC(自动装配模式)
这是默认模式,不需要显式指定组件。Langchain4j会自动从Spring应用上下文中查找并装配所有可用的Langchain4j组件,包括:
ChatModel
StreamingChatLanguageModel
ChatMemory
ChatMemoryProvider
ContentRetriever
RetrievalAugmentor
所有标记为@Tool的方法
2.EXPLICIT(显式装配模式)
当应用中有多个AI服务,并且希望为每个服务指定不同的Langchain4j组件时,就需要使用显式装配模式。
2.流式调用 引入依赖 1 2 3 4 5 6 7 8 9 10 <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-webflux</artifactId > </dependency > <dependency > <groupId > dev.langchain4j</groupId > <artifactId > langchain4j-reactor</artifactId > <version > 1.0.1-beta6</version > </dependency >
配置流式模型对象 之前使用的是阻塞式对话模型对象,在流式调用中,需要使用流式模型对象,故也需要进行配置
1 2 3 4 5 6 7 8 langchain4j: open-ai: streaming-chat-model: base-url: https://api.deepseek.com model-name: deepseek-chat api-key: 自己的apikey log-requests: true log-responses: true
在接口中配置流式模型对象 1 2 3 4 5 6 7 8 9 10 11 @AiService( wiringMode = AiServiceWiringMode.EXPLICIT, // chatModel = "openAiChatModel", //阻塞式模型,模型在容器中的bean名称 streamingChatModel = "openAiStreamingChatModel"//流式模型 ) public interface ChatService { public String chat (String message) ; public Flux<String> fluxChat (String msg) ; }
langchain4j中,会根据方法的返回值来自动选择使用哪个模型
同步返回类型(String、Response等)→ 使用chatModel
流式返回类型(Flux、Publisher等)→ 使用streamingChatModel
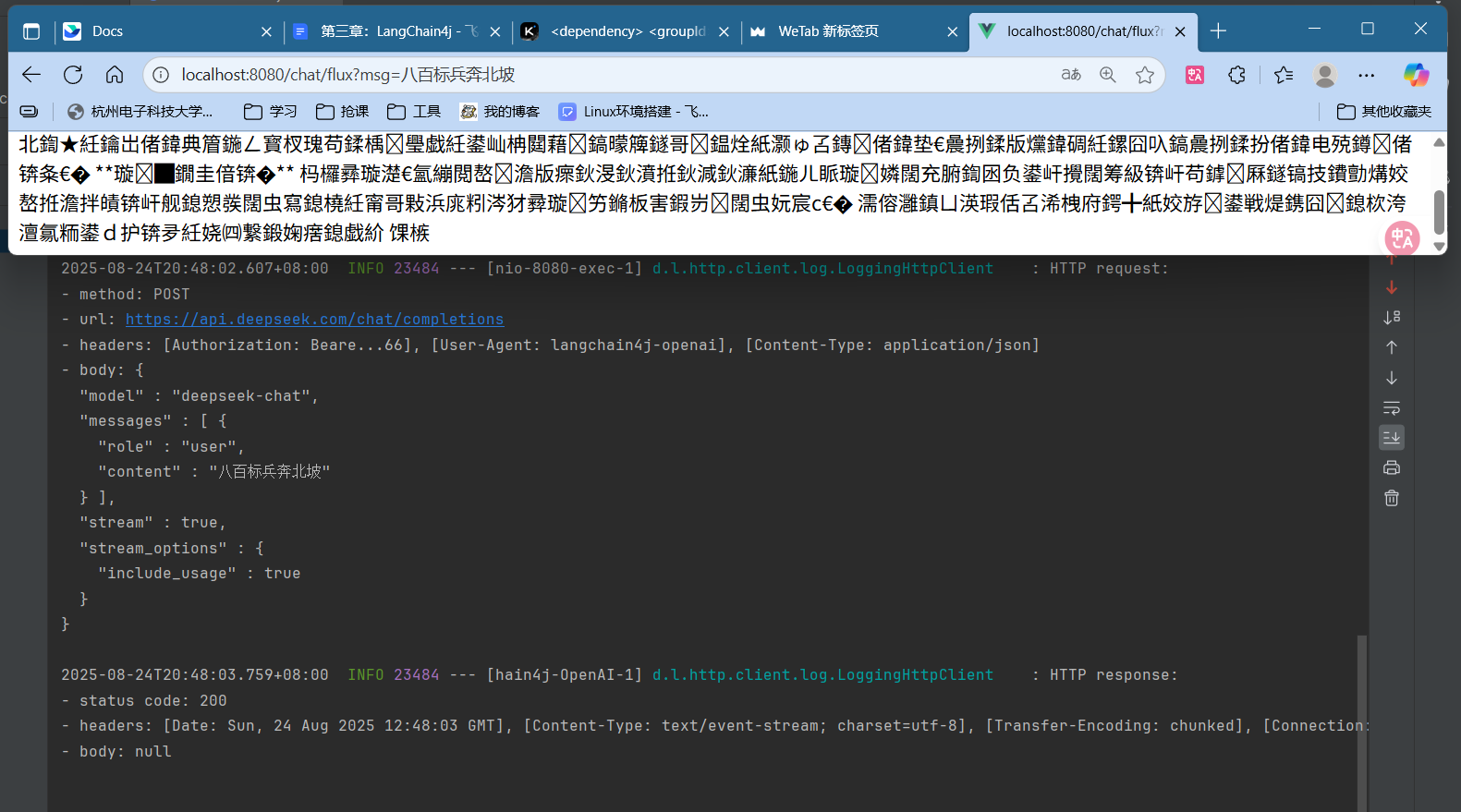
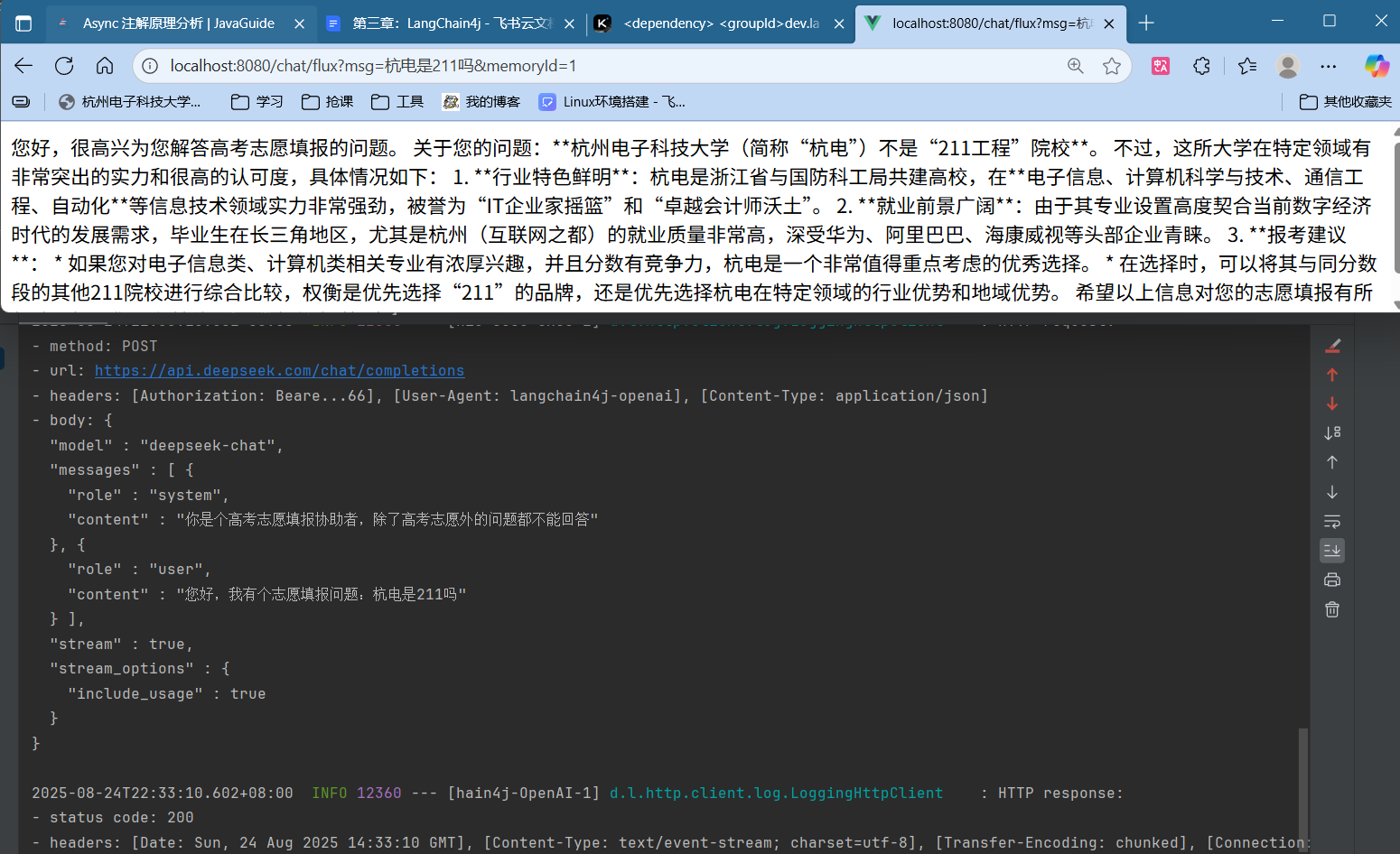
测试 1 2 3 4 5 @GetMapping("/flux") public Flux<String> getFlux (String msg) { Flux<String> res = chatService.fluxChat(msg); return res; }
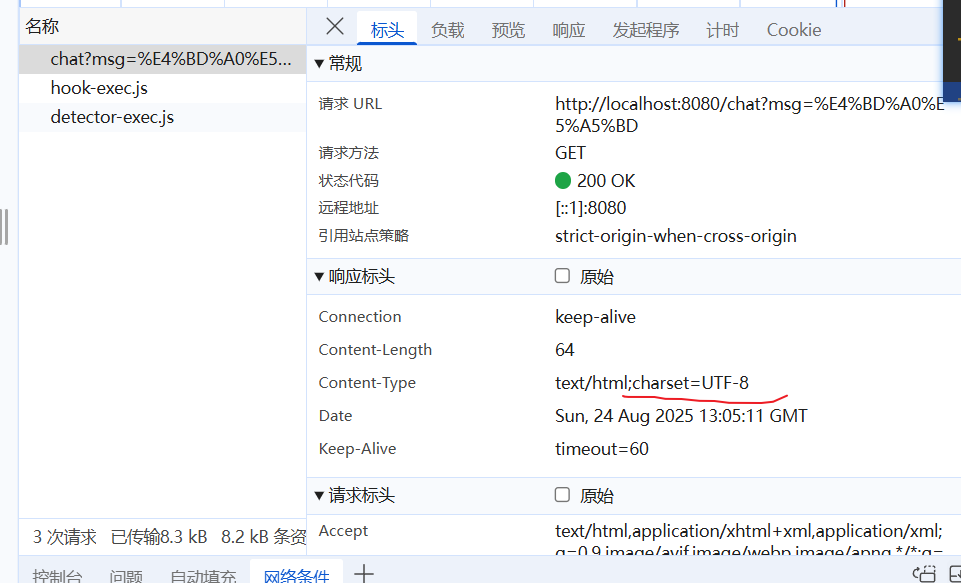
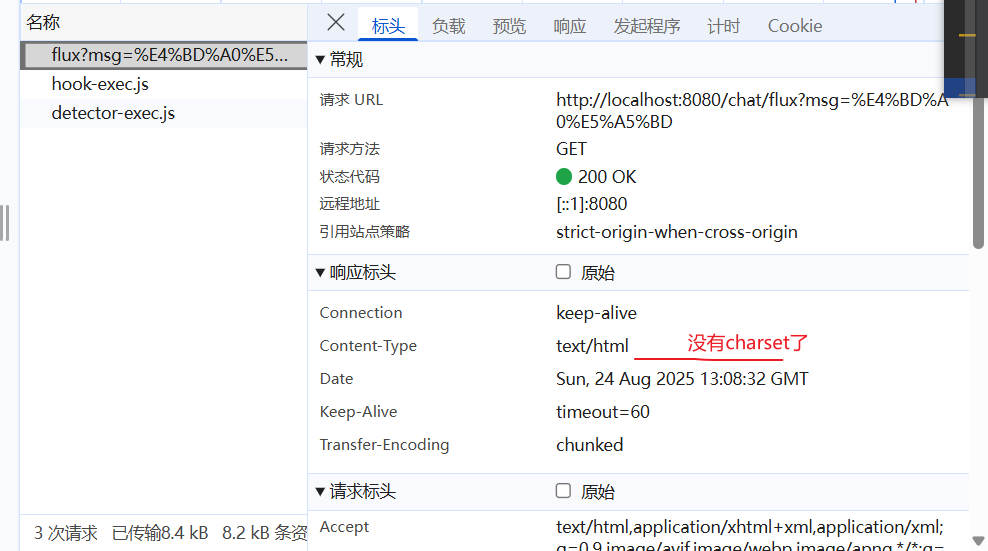
可以看到,浏览器返回了乱码
问题原因 在访问String的get接口时,响应标头携带了utf-8的编码格式,
但在flux接口却没有携带
乱码产生原因还是编码和解码不匹配的问题:
SpringBoot默认使用utf-8进行编码,并在响应头中告诉浏览器编码方式为utf-8。但在流式响应中,没有告诉浏览器编码方式为utf-8,导致浏览器使用默认的解码方式(非utf-8)进行解码,导致乱码问题产生。
解决乱码问题 1 2 3 4 5 @GetMapping(value="/flux", produces = "text/html;charset=utf-8") public Flux<String> getFlux (String msg) { Flux<String> res = chatService.fluxChat(msg); return res; }
produces参数作用:
1.决定请求能不能匹配到这个接口,即判断前端的Accept头里声明的能接收的媒体类型是否符合
2.返回响应时,在响应头中的Content-Type中设置为text/html;charset=指定编码格式
3.消息注解 在langchain4j中提供了两个有关消息的注解,一个是SystemMessage,另一个是UserMessage。
SystemMessage SystemMessage用于设置系统消息,可以直接在接口方法中添加这个注解,然后在注解中添加指定的系统消息即可。如果说消息很长,写在代码中不方便,也可以通过fromResource属性指定外部的文件,这样子可以一次性把系统消息写入到外部文件中,管理起来也很方便。
1 2 3 @SystemMessage(fromResource = "system.txt") public Flux<String> fluxChat (String msg) ;
UserMessage @UserMessage可以帮助我们把用户传递的消息拼接上我们预设的消息,使用方式如下,注意使用{{}}和@V注解进行绑定。
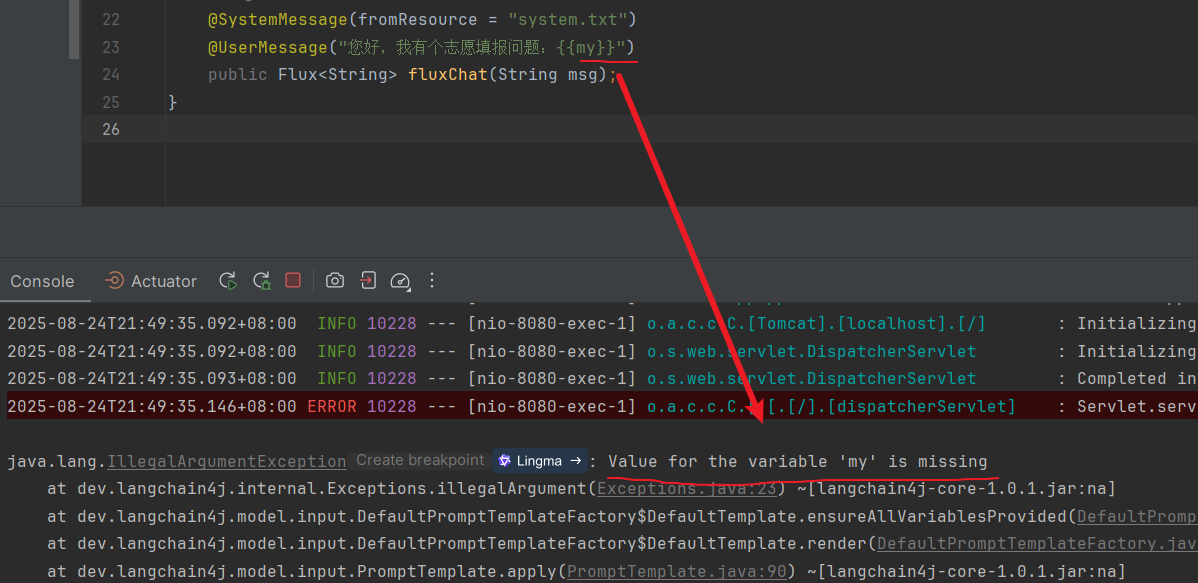
1 2 3 4 5 6 7 8 @SystemMessage(fromResource = "system.txt") @UserMessage("您好,我有个志愿填报问题:{{it}}") public Flux<String> fluxChat (String msg) ;@UserMessage("您好,我是{{name}}, 想请教您:{{msg}}") public String chat2 (@V("name") String msg1, @V("msg") String msg2) ;
这里有一点需要说明,在没有@V情况下,这个花括号内的it是固定的,不能随便写(写了别的就会报异常)。假设你不想使用it这个名字,langchain4j提供了一个V注解,用于解决这个问题。我们在参数前面通过V注解给这个参数起一个名字,然后在花括号内写上同样的名字就能获取到了。
测试 以上面的接口配置为准,单参测试
多参测试
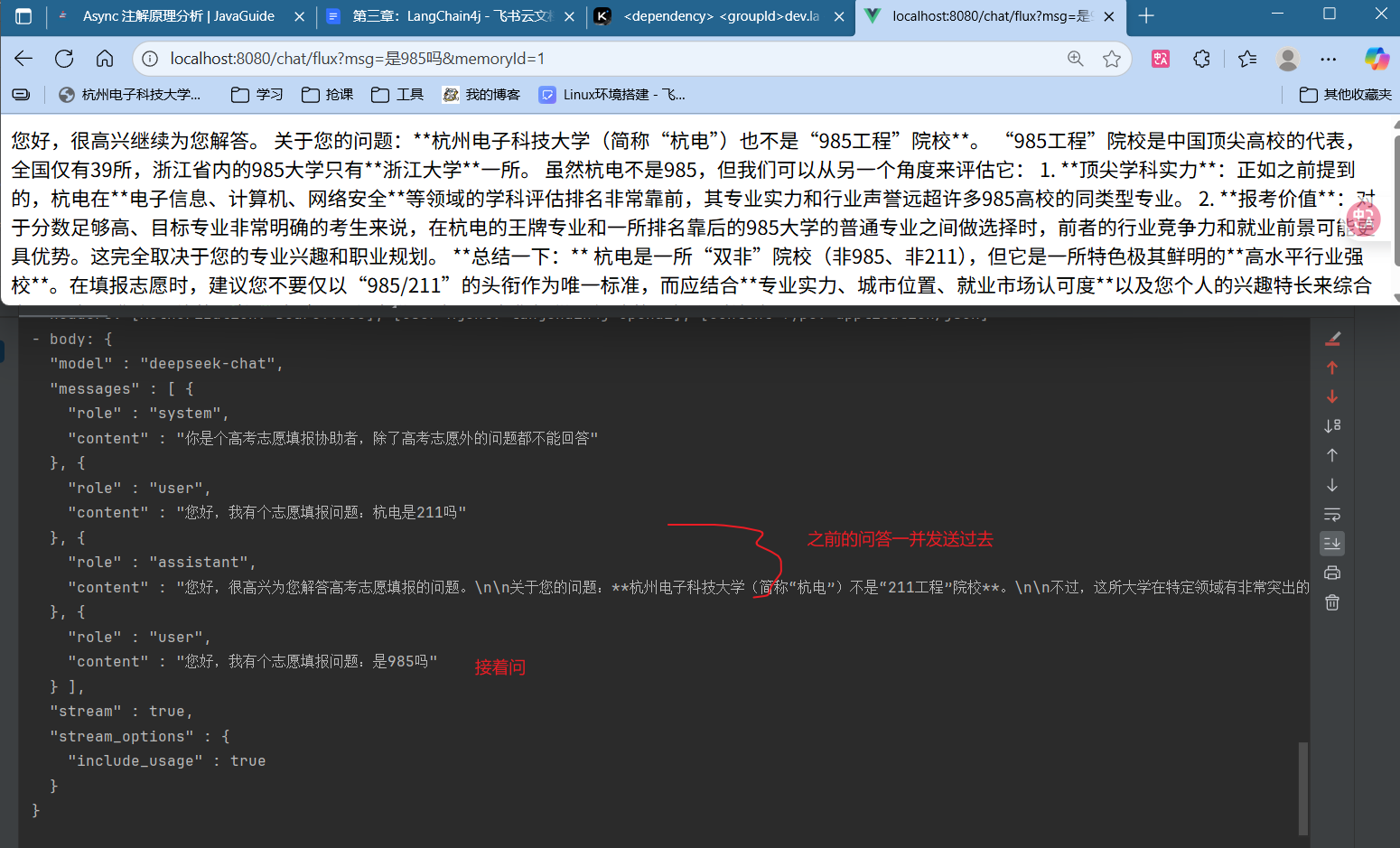
4.会话记忆 大模型是如何记住我们之前的问题的,来回答后续的问题的呢?答案就是在当前问题发送的同时,将之前的问题和回答一并发送了过去 !!!这就是会话记忆的实现方式。
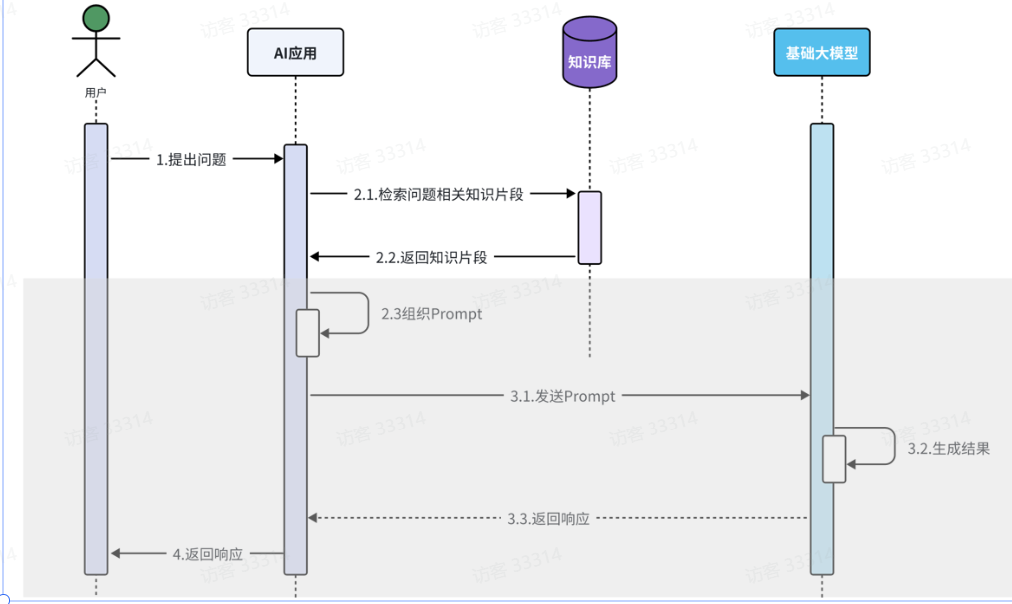
4.1实现原理 来源:第三章:LangChain4j - 飞书云文档
当用户问西北大学是211吗?它会把消息传递给后端,后端接收到消息后,会自动把消息存放到存储对象中,然后再获取存储对象中记录的所有会话消息,一块发送给大模型,当然现在存储对象中只记录了一条消息,所以只把一条消息发送给大模型。大模型根据接收到的消息,生成答案,比如说是的,再把答案响应给web后端,此时web后端会把得到的响应消息往存储对象中拷贝一份,然后再把响应消息发送给用户。
用户接收到答案后,接着问,是985吗?这条消息发送给web后端后,web后端依然会自动的把消息存放到存储对象中,此时存储对象中就存放了三条消息了,紧接着获取到存储对象中所有的会话消息,一并发送给大模型,这一次大模型就能够根据用户发送的所有会话记录进行推断回答了,这就是会话记忆的原理!
4.2基本实现 langchain4j提供了一个接口叫做ChatMemory ,该接口中提供了add方法用于添加一条记录,messages方法用于获取所有的会话记录,clear方法用于清除所有的会话记录,这里还有一个id方法,它是用于唯一的标识一个存储对象。
定义会话记忆对象 在配置类中创建ChatMemory的实现类并注册到IOC容器中。
1 2 3 4 5 6 @Bean ChatMemory chatMemory () { return MessageWindowChatMemory.builder() .maxMessages(20 ) .build(); }
配置会话记忆对象 配置到AiService中
1 2 3 4 5 6 7 8 9 @AiService( wiringMode = AiServiceWiringMode.EXPLICIT, // chatModel = "openAiChatModel", //阻塞式模型,模型在容器中的bean名称 streamingChatModel = "openAiStreamingChatModel",//流式模型 chatMemory = "chatMemory" //配置会话记忆对象,填入bean名称 ) public interface ChatService { }
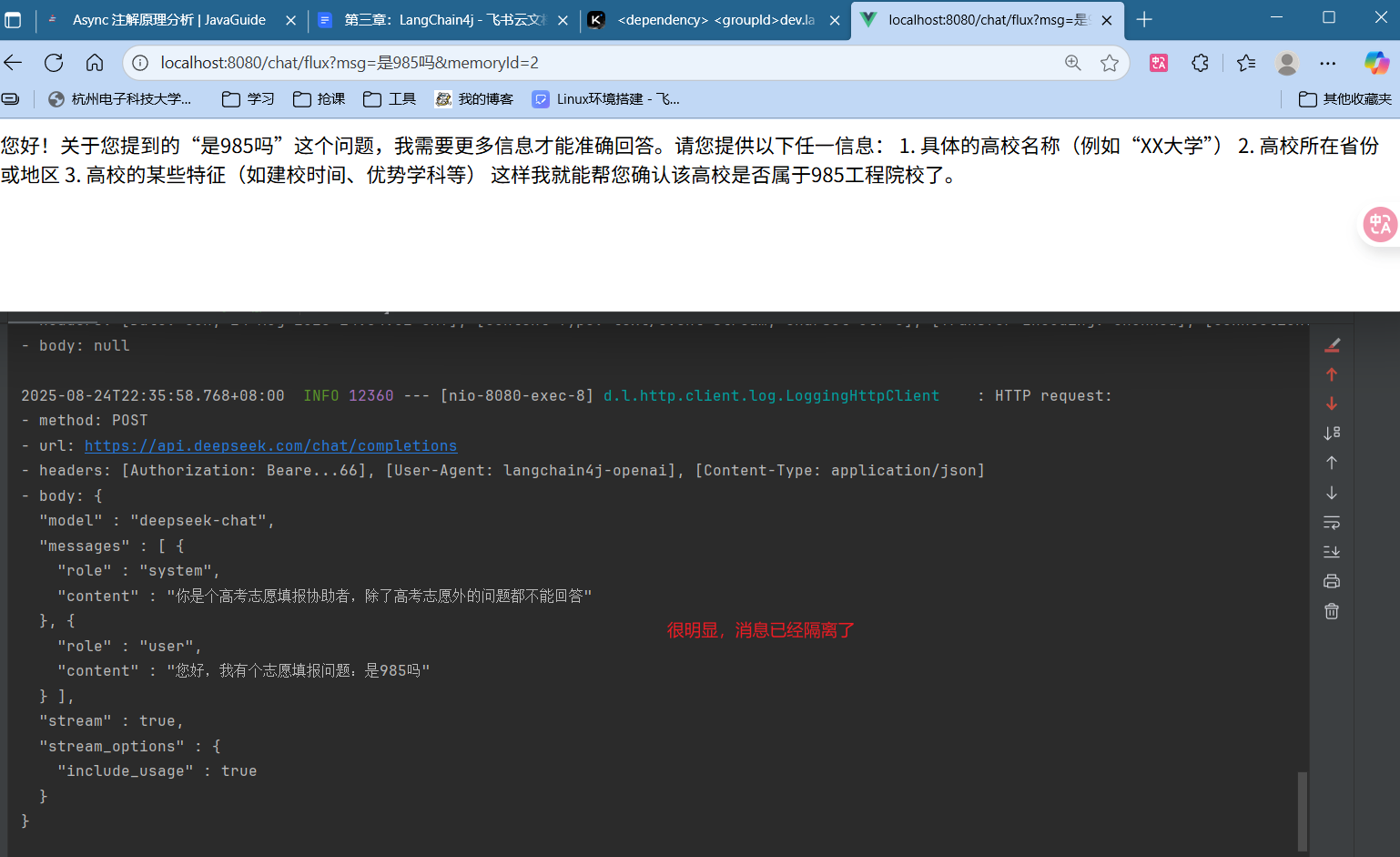
4.3会话记忆隔离 上述的配置和实现并没有区分访问的用户对象,导致不同用户会共用同一个会话记忆对象。
要实现会话记忆隔离,就要使用唯一标识(id)来标记会话记忆对象。
在LangChain4j中可以准备一个容器,专门用于存储当前程序中所有的会话记忆对象。假设有一个用户访问我们的程序,此时它除了要把用户问题message携带给后端,还需要携带一个memoryId,假设它携带的memoryId为1,此时LangChain4j会先从容器中找有没有一个ChatMemory对象的id为1,如果有就使用,但是很明显现在没有。所以它会新创建一个ChatMemory对象,并把当前的memoryId 1 设置给这个ChatMemory对象,并把会话记录存储到该对象中使用。
假设又有一个用户访问我们的程序,它携带的memoryId为2,同样的,LangChain4j也会从容器中找有没有一个ChatMemory对象的id为2,很显然还是没有,所以会创建一个新的ChatMemory对象,并把memoryId 2设置给这个ChatMemory对象,并把会话记录存储到该对象中使用。
注意,假设第二个用户继续访问我们的程序,它携带了同样的memoryId 2给后端,此时LangChain4j从容器中查找的时候发现已经存在一个ChatMemory对象的id为2,所以直接复用这个已经存在的ChatMemory对象,这样我们就可以借助于ChatMemory的id值实现不同会话之间的记忆隔离效果。
定义会话记忆对象提供者 因为要区分不同的会话对象,所以需要创建一个能根据传入的id创建不同ChatMemory的对象。
1 2 3 4 5 6 7 8 9 10 11 12 @Bean ChatMemoryProvider chatMemoryProvider () { return new ChatMemoryProvider () { @Override public ChatMemory get (Object memoryId) { return MessageWindowChatMemory.builder() .id(memoryId) .maxMessages(20 ) .build(); } }; }
配置会话记忆对象提供者 这里原先的charMemory就不需要了,因为它仅仅是固定一个对象,而我们需要的是根据id的不同创建能新的chatMemory对象的提供者来获取或者创建chatMemory。
1 2 3 4 5 6 7 8 9 10 @AiService( wiringMode = AiServiceWiringMode.EXPLICIT, // chatModel = "openAiChatModel", //阻塞式模型,模型在容器中的bean名称 streamingChatModel = "openAiStreamingChatModel",//流式模型 //chatMemory = "chatMemory", //会话记忆对象 chatMemoryProvider = "charMemoryProvider" //会话记忆对象提供者 ) public interface ChatService { }
接口添加MemoryId参数 使用@MemoryId注解
1 2 3 @SystemMessage(fromResource = "system.txt") @UserMessage("您好,我有个志愿填报问题:{{it}}") public Flux<String> fluxChat (@MemoryId String memoryId, @V("it") String msg) ;
Controller添加MemoryId参数 1 2 3 4 5 @GetMapping(value="/flux", produces = "text/html;charset=utf-8") public Flux<String> getFlux (String memoryId, String msg) { Flux<String> res = chatService.fluxChat(memoryId, msg); return res; }
测试 memoryId=1时测试
memory=2继续测试
问题 配置提供者后,是如何判断id对应的会话对象是否已经存在的?
核心概念澄清
1 2 3 4 5 6 7 8 9 10 11 12 13 @Bean ChatMemoryProvider chatMemoryProvider () { return new ChatMemoryProvider () { @Override public ChatMemory get (Object id) { return MessageWindowChatMemory.builder() .id(id) .chatMemoryStore(myChatMemoryStore) .maxMessages(20 ) .build(); } }; }
源码解读
ChatMemory的实现类MessageWindowChatMemory的部分源码+解读
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 public class MessageWindowChatMemory implements ChatMemory { private final Object id; private final Integer maxMessages; private final ChatMemoryStore store; public Builder id (Object id) { this .id = id; return this ; } public void add (ChatMessage message) { List<ChatMessage> messages = this .messages(); if (message instanceof SystemMessage) { Optional<SystemMessage> systemMessage = findSystemMessage(messages); if (systemMessage.isPresent()) { if (((SystemMessage)systemMessage.get()).equals(message)) { return ; } messages.remove(systemMessage.get()); } } messages.add(message); ensureCapacity(messages, this .maxMessages); this .store.updateMessages(this .id, messages); } public List<ChatMessage> messages () { List<ChatMessage> messages = new LinkedList (this .store.getMessages(this .id)); ensureCapacity(messages, this .maxMessages); return messages; } }
ChatMemoryStore的实现类InMemoryChatMemoryStore解读
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 public interface ChatMemoryStore { List<ChatMessage> getMessages (Object var1) ; void updateMessages (Object var1, List<ChatMessage> var2) ; void deleteMessages (Object var1) ; } public class InMemoryChatMemoryStore implements ChatMemoryStore { private final Map<Object, List<ChatMessage>> messagesByMemoryId = new ConcurrentHashMap (); public InMemoryChatMemoryStore () { } public List<ChatMessage> getMessages (Object memoryId) { return (List)this .messagesByMemoryId.computeIfAbsent(memoryId, (ignored) -> { return new ArrayList (); }); } public void updateMessages (Object memoryId, List<ChatMessage> messages) { this .messagesByMemoryId.put(memoryId, messages); } public void deleteMessages (Object memoryId) { this .messagesByMemoryId.remove(memoryId); } }
从源码中可以知道,当一个用户传入会话id和会话时,会先根据id创建一个新的ChatMemory对象,然后,再调用add方法传入用户当前的消息,在add方法中,它会往它关联的store对象中先读取历史会话列表,在把当前消息添加到列表末尾,最后调用Store对象的updateMessages方法,对InMemoryChatMemoryStore对象维护的Map中,根据会话ID,进行会话列表的更新。
所以,简单来说,真正存储会话id和会话列表的是ChatMemoryStore对象,ChatMemory对象只是用来操作Store对象的,并不存储消息,Provider对象只是用来创建ChatMemory对象的。
ok,完成了上面的源码解读还是挺爽的。
4.4会话记忆持久化 上面我们已经知道了ChatMemoryStore是如何存储会话记录的,那么问题来了,如果使用已有的ChatMemoryStore实现类,那么当服务器重启时,数据就会丢失,所以我们需要自己去创建ChatMemoryStore的实现,来实现用中间件,比如用redis持久化存储消息。
下面就使用redis来实现会话的持久化存储
引入依赖 1 2 3 4 <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-data-redis</artifactId > </dependency >
配置redis连接信息 1 2 3 4 5 spring: data: redis: host: 自己的redis的ip地址 port: 6379
自定义ChatMemoryStore对象的实现类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 @Component public class RedisChatMemoryStore implements ChatMemoryStore { @Autowired StringRedisTemplate template; private static String prefix = "chat_memoryId_" ; @Override public List<ChatMessage> getMessages (Object o) { String message = template.opsForValue().get(prefix + o); List<ChatMessage> chatMessages = ChatMessageDeserializer.messagesFromJson(message); return chatMessages; } @Override public void updateMessages (Object o, List<ChatMessage> list) { String message = ChatMessageSerializer.messagesToJson(list); template.opsForValue().set(prefix+o, message); } @Override public void deleteMessages (Object o) { template.delete(prefix + o); } }
注意,这里使用了ChatMessageSerializer和ChatMessageDeserializer提供的序列化和反序列化方法。
在ChatMemoryProvider中配置自定义实现类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 @Configuration public class CommonConfig { @Autowired OpenAiChatModel model; @Autowired RedisChatMemoryStore redisChatMemoryStore; @Bean ChatMemoryProvider chatMemoryProvider () { ChatMemoryProvider chatMemoryProvider = new ChatMemoryProvider () { @Override public ChatMemory get (Object o) { ;return MessageWindowChatMemory.builder() .id(o) .chatMemoryStore(redisChatMemoryStore) .maxMessages(20 ) .build(); } }; return chatMemoryProvider; } }
测试 完美存储到redis中,测试时我注意到消息的存储流程正是,用户发送消息 -> 消息存储到redis -> 发送消息给大模型 -> 大模型生成回答 -> 回答存入redis -> 返回给前端
感想 会话记忆中的主要的三个接口设置的实在是太妙了,由ChatMemoryStore负责会话记录的增删改,ChatMemory负责消息的业务逻辑操作,比如拼接会话记录并存入到store对象中,ChatMemoryProvider则类似于工厂,提供ChatMemory对象的实例。极大程度上进行了解耦,方便扩展。
职责分离 (Separation of Concerns)
ChatMemoryStore: 专注于数据的持久化和检索
ChatMemory: 专注于消息的处理和操作
ChatMemoryProvider: 专注于实例的创建和管理
高内聚低耦合 (High Cohesion, Low Coupling)
5.RAG知识库 5.1RAG原理 RAG(Retrieval Augmented Generation),就是检索增强生成。简单来说,就是通过检索外部知识库的方式增强大模型的生成能力。
当大模型训练完毕后,随着时间的推移产生的新数据大模型是无法感知的,而且训练大模型的时候一般使用的都是通用的训练数据,有关专业领域的知识,大模型也是不知道的。所以,如果要想让大模型能根据最新的数据或者专业领域的数据回答问题,我们就需要给它外挂一个知识库,这就是rag要做的事情。
外挂知识库后的工作流程如下:
当用户把问题发给AI应用(后端)时,AI应用会先根据用户的问题,从知识库中检索出对应的知识片段一并发送给大模型 。大模型会根据问题和知识库中检索到的知识来生成最终的结果给AI应用,最终在返回给用户。
我们需要关注的问题有两个,一个是知识库应该怎么搭建 ,另一个是如何从知识库中检索出用户问题相关的知识片段 。
这个知识库一般采取的是一种特殊的数据库,叫向量数据库。目前市面上常见的向量数据库有很多,比如Milvus、Chroma、Pinecone这些专用的向量数据库,还有一些传统的数据库做了向量化扩展,比如redis提供了RedisSearch用于完成向量存储,PostgreSql提供了pgvetor用于完成向量存储,不管是哪一种向量数据库原理都是一样的,使用也都大差不差。
检索知识片段主要是根据问题向量和知识库中各知识片段向量之间的余弦相似度比较来获取的。余弦相似度越大,向量的方向越接近。
5.2RAG快速入门–存储 引入依赖 1 2 3 4 5 6 <dependency > <groupId > dev.langchain4j</groupId > <artifactId > langchain4j-easy-rag</artifactId > <version > 1.0.1-beta6</version > </dependency >
创建数据库知识文档 首先,可以借助ai,随机生成一份知识文档,我这里用kimi生成了一个猫咪日常护理知识文档
构建向量数据操作对象EmbeddingSotre 1 2 3 4 5 6 7 8 9 10 11 12 13 @Bean public EmbeddingStore sotre () { List<Document> documents = ClassPathDocumentLoader.loadDocuments("content" ); InMemoryEmbeddingStore store = new InMemoryEmbeddingStore (); EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder() .embeddingStore(store) .build(); ingestor.ingest(documents); return store; }
ingestor.ingest(documents)这一行代码的作用是将加载的文档进行预处理,包括分割、向量化,并将结果存储在向量数据库中。
InMemoryEmbeddingSotre对象负责向量的存储,其内部维护了一个CopyOnWriteArrayList对象用于存储
1 2 3 4 5 6 7 8 9 10 public class InMemoryEmbeddingStore <Embedded> implements EmbeddingStore <Embedded> { final CopyOnWriteArrayList<Entry<Embedded>> entries; static class Entry <Embedded> { String id; Embedding embedding; Embedded embedded; } }
CopyOnWriteArrayList<Entry<Embedded>> entries:
这是 InMemoryEmbeddingStore 类中的核心存储结构
它是一个线程安全的列表,用于存储所有嵌入向量和对应的文本内容
CopyOnWriteArrayList 是一种适合读多写少场景的并发容器
Entry<Embedded>:
这是存储的元素类型,是静态内部类
Entry 是一个内部类,包含两个主要部分:
嵌入向量(embedding)
对应的嵌入内容(embedded),通常是文本段落
5.3检索 构建ContentRetriever对象 Langchain4j提供的向量数据库检索对象叫做ContentRetriever,构建时可以设置如下三个内容
1 2 3 4 5 6 7 8 9 @Bean public ContentRetriever contentRetriever (EmbeddingStore store) { return EmbeddingStoreContentRetriever.builder() .embeddingStore(store) .minScore(0.5 ) .maxResults(3 ) .build(); }
配置ContentRetriever对象 回到之前的封装聊天方法的接口中,增加如下内容检索参数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 @AiService( wiringMode = AiServiceWiringMode.EXPLICIT, //手动配置 chatModel = "openAiChatModel", //指定模型 streamingChatModel = "openAiStreamingChatModel", // chatMemory = "chatMemory" chatMemoryProvider = "chatMemoryProvider", //配置会话记忆提供者对象 contentRetriever = "contentRetriever" //配置向量数据库检索对象 ) public interface ChatService { public String chat (String message) ; @UserMessage("您好,我是{{name}}, 想请教您:{{msg}}") public String chat2 (@V("name") String msg1, @V("msg") String msg2) ; @SystemMessage(fromResource = "system.txt") @UserMessage("您好,我有个问题:{{it}}") public Flux<String> fluxChat (@MemoryId String memoryId, @V("it") String msg) ; }
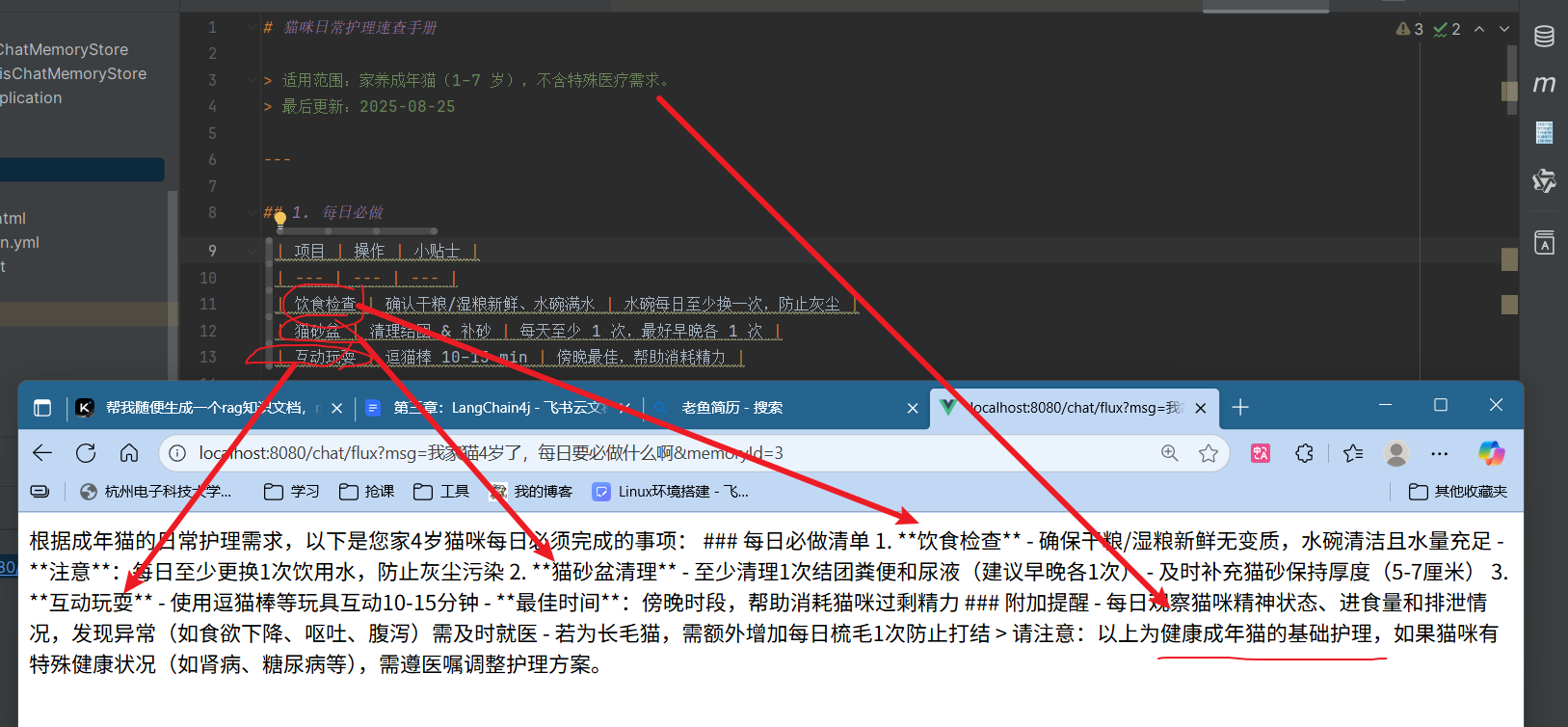
测试 重新设置系统消息
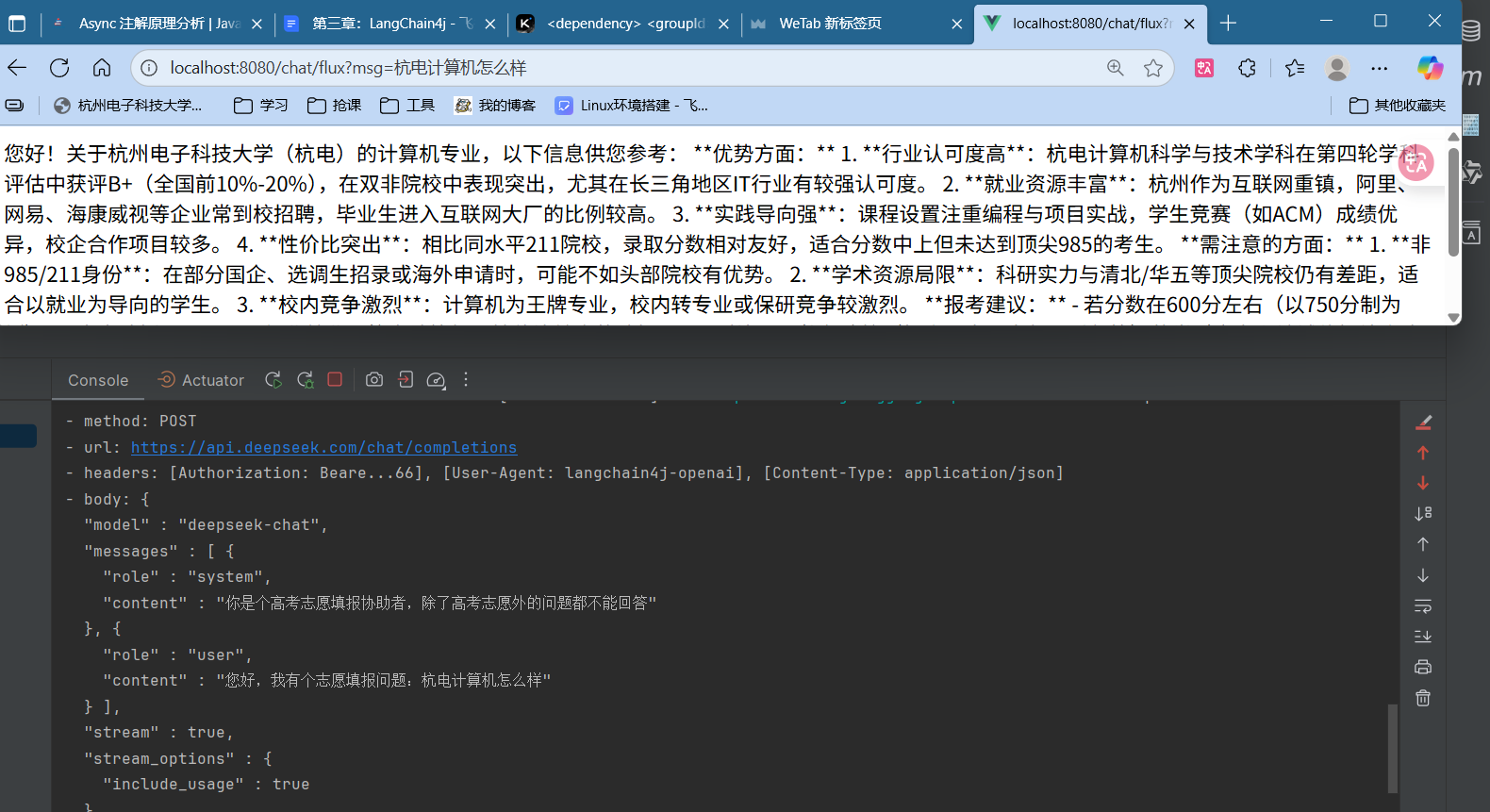
可以很明显看到,ai生成的结果利用了我们提供的rag知识库
这里可以看到,是把rag知识库中的内容一并发送给ai,让ai根据知识库的内容进行回答
5.4核心API
核心流程就是
准备存储数据的文档
-> 使用文档加载器 加载进内存
-> 由于加载过程中,需要使用解析文档内容,所以还要使用到文档解析器 解析文档
-> 解析之后,每个文档对应一个Document对象。但如果直接把整个文档内存一次性向量化到数据中并不利于检索,所以需要使用文档分割器 分割文档内容为一个个的文本片段
-> 得到文本判断还不够,我们必须知道文本片段的向量值,所以需要使用向量模型 将所有文本片段转化为一个个的向量,得到Embedding对象存储向量、Embedde对象对应文本内片段
-> 最后,使用EmbeddingStore这种向量数据库操作对象 ,将向量和对应的文本片段存储到向量数据库中
在整个流程中,主要用到了文档加载器、文档解析器、文档分割器、向量模型以及向量数据库操作对象这五类API。其中有关文档分割器、向量模型、还有向量数据库操作对象的具体方法的调用都被封装到了EmbeddingStoreIngestor中了,无需过多关注,我们主要关注的是使用哪种文档分割器、哪种向量模型、哪种向量数据库操作对象即可,将来用哪种把哪种交给EmbeddingStoreIngestor就可以了
5.4.1文档加载器 文档加载器的作用是把磁盘或者网络中的数据加载进程序。LangChain4j给我们提供了多个文档加载器,其中常见的有以下三种:
FileSystemDocumentLoader, 根据本地磁盘绝对路径加载
ClassPathDocumentLoader,相对于类路径加载
UrlDocumentLoader,根据url路径加载
1 2 3 4 5 6 List<Document> documents = ClassPathDocumentLoader.loadDocuments("rag" ); FileSystemDocumentLoader.loadDocument("E:\\java_project\\SpringAIProject\\langchain4jProject\\src\\main\\resources\\rag\\cat.md" ); UrlDocumentLoader.load("http://test/cat.md," , new TextDocumentParser ());
5.4.2文档解析器 文档解析器就是用于解析文档中的内容,把原本非纯文本数据转化成纯文本。比如初始的文档是pdf格式的,它的内容就不是纯文本的,此时需要借助于文档解析器将非纯文本数据转化成纯文本。在LangChain4j中提供了几个常用的文档解析器:
TextDocumentParser,解析纯文本格式的文件
ApachePdfBoxDocumentParser,解析pdf格式文件
ApachePoiDocumentParser,解析微软的office文件,例如DOC、PPT、XLS
ApacheTikaDocumentParser(默认),几乎可以解析所有格式的文件
默认的ApacheTikaDocumentParser虽然可以解析所有格式的文件,但是它可能在纯PDF文件方面的表现没有那么优秀,或者使用起来没有那么方便,此时我们可以将默认的解析器切换成ApachePdfBoxDocumentParser。但需要引入指定的依赖
1 2 3 4 5 <dependency > <groupId > dev.langchain4j</groupId > <artifactId > langchain4j-document-parser-apache-pdfbox</artifactId > <version > 1.0.1-beta6</version > </dependency >
5.4.3文档分割器 文档分割器主要用于把一个大的文档切割成一个一个的小片段。在langchain4j中提供了多种文档分割器,大概有以下7种:
DocuemntByParagraphSplitter,按照段落分割文本
DocumentByLineSplitter,按照行分割文本
DocumentBySentenceSplitter,按照句子分割文本
DocumentByWordSplitter,按照词分割文本
DocumentByCharacterSplitter,按照固定数量的字符分割文本
DocumentByRegexSplitter,按照正则表达式分割文本
DocumentSplitters.recursive(…)(默认),递归分割器,优先段落分割,再按照行分割,再按照句子分割,再按照词分割
如果我们需要使用自定义规则的文档分割器,示例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 @Bean public EmbeddingStore sotre () { List<Document> documents = ClassPathDocumentLoader.loadDocuments("rag" ); InMemoryEmbeddingStore store = new InMemoryEmbeddingStore (); EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder() .embeddingStore(store) .documentSplitter(DocumentSplitters.recursive( 300 , 10 )) .build(); ingestor.ingest(documents); return store; }
5.4.4向量模型 向量模型的作用是把分割后的文本片段向量化或者把用户消息向量化。
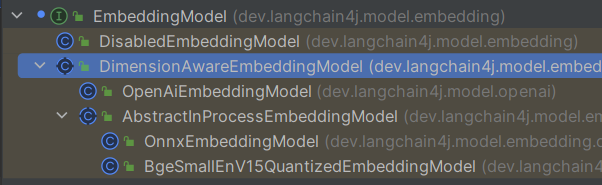
向量模型EmbeddingModel本身只是一个接口
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public interface EmbeddingModel { default Response<Embedding> embed (String text) { return this .embed(TextSegment.from(text)); } default Response<Embedding> embed (TextSegment textSegment) { Response<List<Embedding>> response = this .embedAll(Collections.singletonList(textSegment)); ValidationUtils.ensureEq(((List)response.content()).size(), 1 , "Expected a single embedding, but got %d" , new Object []{((List)response.content()).size()}); return Response.from((Embedding)((List)response.content()).get(0 ), response.tokenUsage(), response.finishReason()); } Response<List<Embedding>> embedAll (List<TextSegment> var1) ; default int dimension () { return ((Embedding)this .embed("test" ).content()).dimension(); } }
它有内置的实现类供使用
但这种内置的向量模型可能因为支持的向量纬度太少而导致功能没有那么强大,所以有些时候需要替换它,使用一些功能更加强大的向量模型。这里我们可以使用阿里百炼平台的向量模型,让其帮我们生成各个文本片段的向量。使用方式如下
这里需要获取自己的apikey,然后从向量模型中选一个模型的名称和参考api文档的baseurl,填入下面的配置文件中即可
配置文件
1 2 3 4 5 6 7 8 langchain4j: open-ai: embedding-model: base-url: https://dashscope.aliyuncs.com/compatible-mode/v1 api-key: 自己的apikey model-name: text-embedding-v3 log-requests: true log-responses: true
设置向量模型
因为配置文件中已经填入了相关参数,spring会自动注册一个Embedding对象,我们只需要依赖注入即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 @Configuration public class CommonConfig { @Autowired EmbeddingModel embeddingModel; @Bean public EmbeddingStore sotre () { List<Document> documents = ClassPathDocumentLoader.loadDocuments("rag" ); InMemoryEmbeddingStore store = new InMemoryEmbeddingStore (); EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder() .embeddingStore(store) .documentSplitter(DocumentSplitters.recursive( 300 , 10 )) .embeddingModel(embeddingModel) .build(); ingestor.ingest(documents); return store; } }
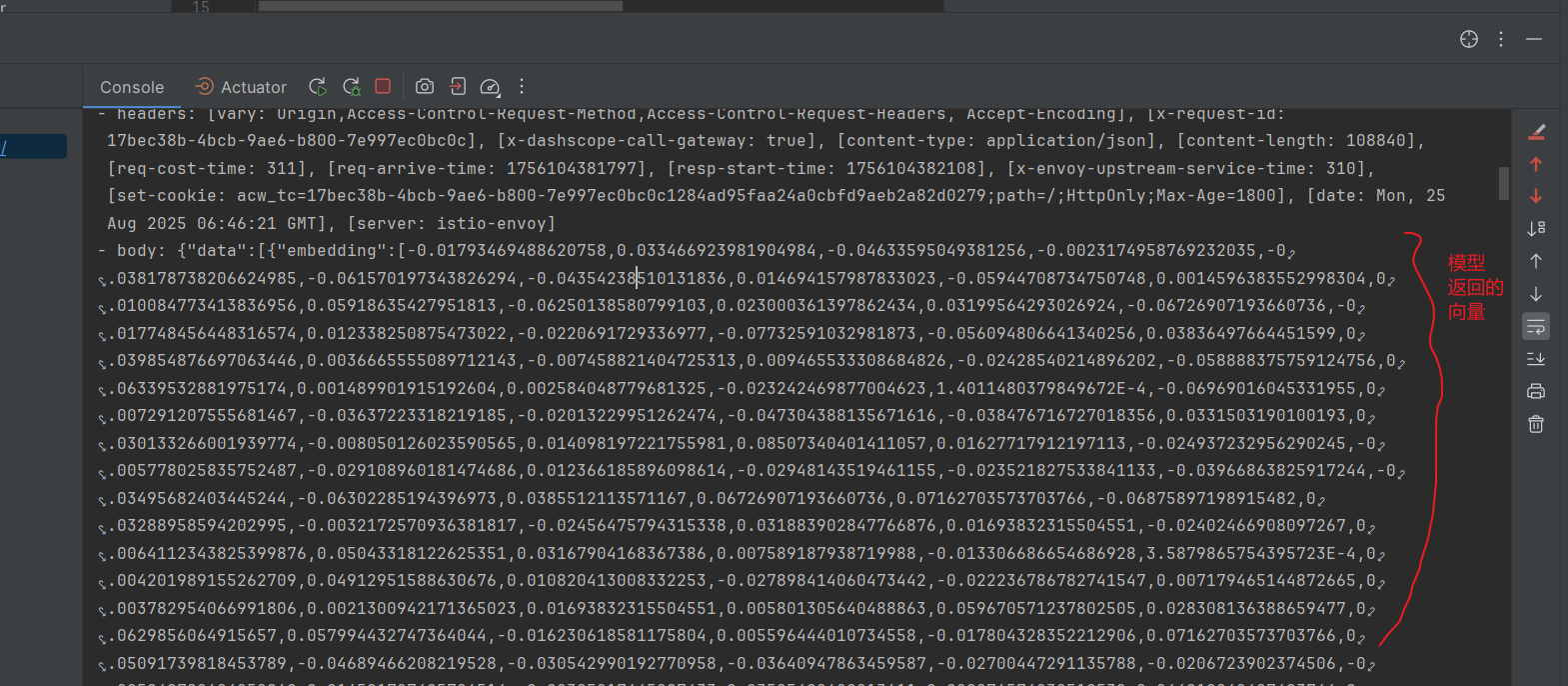
启动项目可以在日志看到一个文本片段对应的向量的数值数组有这么大
5.4.5向量数据库操作对象 EmbeddingStore是用来操作向量数据库的对象接口,将来不管是存储还是检索都需要借助于它来完成。LangChain4j提供的EmbeddingStore接口中提供了两组方法,分别是add用于存储数据,search用于检索数据。
之前,我们配置类中是使用其内置的实现类ImMemoryEmbedding来存储向量的,这种情况跟会话记忆一样,当服务器重启时,数据就丢失了,需要重新加载,所以我们同样可以使用数据库来存储向量数据
这里我使用docker安装向量数据库RediSearch
1 2 3 docker stop redis docker rm redis docker run --name redis-vector -d -p 6379:6379 redislabs/redisearch
引入依赖
1 2 3 4 5 <dependency > <groupId > dev.langchain4j</groupId > <artifactId > langchain4j-community-redis-spring-boot-starter</artifactId > <version > 1.0.1-beta6</version > </dependency >
配置向量数据库连接信息
1 2 3 4 5 langchain4j: community: redis: host: 192.168 .10 .101 port: 6379
注入RedisEmbeddingStore对象并使用
和向量模型一样,配置好文件后就会自动把RedisEmbeddingStore注册到IOC容器中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 @Autowired EmbeddingModel embeddingModel; @Autowired RedisEmbeddingStore redisEmbeddingStore; @Bean public EmbeddingStore sotre () { List<Document> documents = ClassPathDocumentLoader.loadDocuments("rag" ); InMemoryEmbeddingStore store = new InMemoryEmbeddingStore (); EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder() .embeddingStore(redisEmbeddingStore) .documentSplitter(DocumentSplitters.recursive( 300 , 10 )) .embeddingModel(embeddingModel) .build(); ingestor.ingest(documents); return store; }
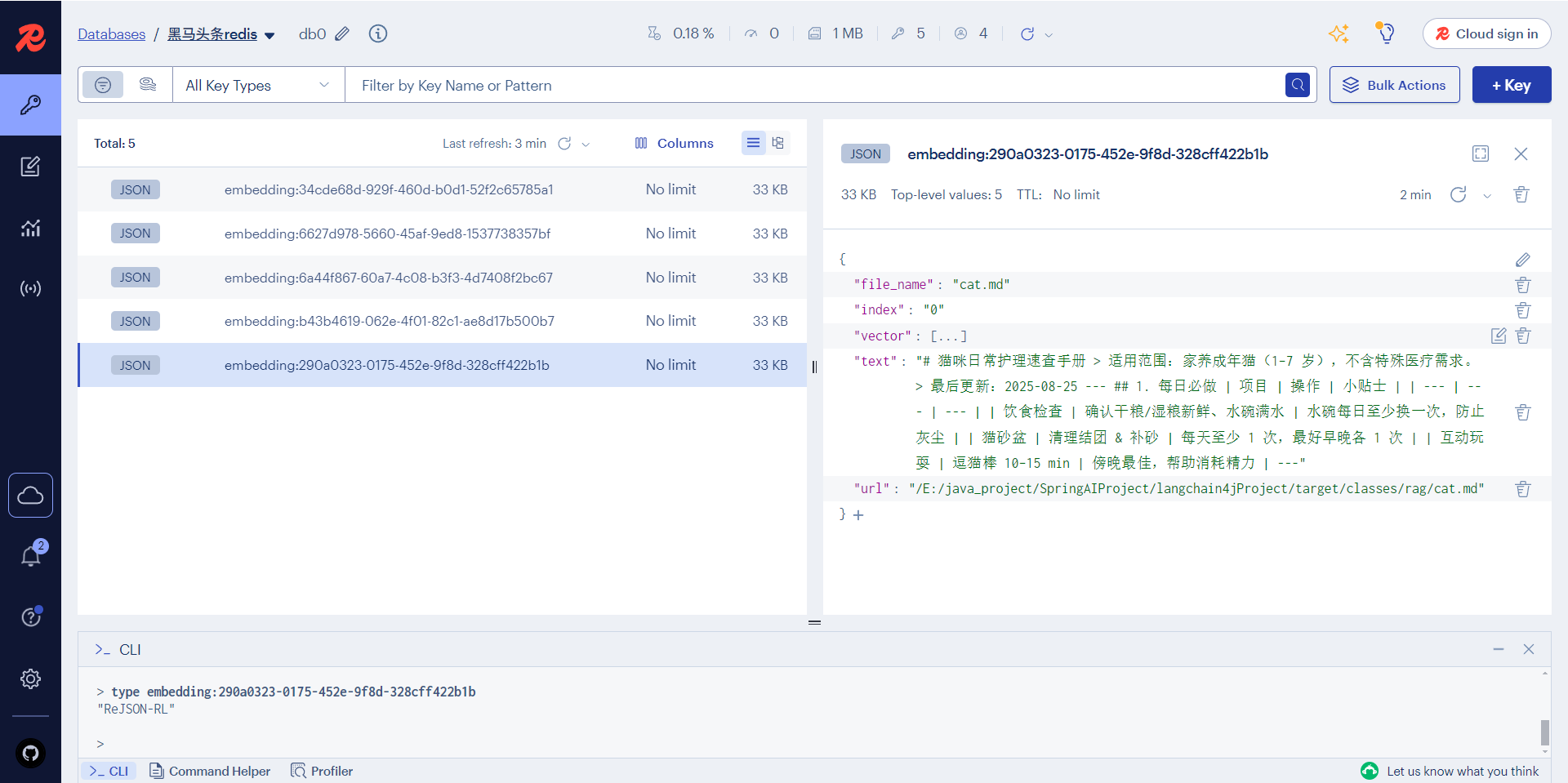
测试 启动项目,打开redisInsight查看数据是如何存储的
一条文本片段居然被拆分成了容量为1000多的数组vector向量,恐怖如斯
同时,我们也可以看到,这里使用了ReJSON-RL的数据结构来存储数据。普通的redis并不支持这个数据结构,需要安装对应模块才行。
为了避免程序每次启动都要重新加载文档的向量到数据库中,在启动完成一遍之后,向量和文本就已经存储到redisSearch中了,我们就不需要重新切分文档并存储了,直接使用redisEmbeddingStore对象即可。
但注意,在向量检索对象的构造上,一定要指定向量模型,因为我现在设置向量模型在向量数据库操作对象上,如果不指定的话,测试时会报向量维度不匹配的错误。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 @Configuration public class CommonConfig { @Autowired EmbeddingModel embeddingModel; @Autowired RedisEmbeddingStore redisEmbeddingStore; @Bean public ContentRetriever contentRetriever () { return EmbeddingStoreContentRetriever.builder() .embeddingStore(redisEmbeddingStore) .minScore(0.5 ) .maxResults(3 ) .embeddingModel(embeddingModel) .build(); } }
总结 Langchain4j中搭建RAG知识库其实并不复杂,流程是通透的,主要涉及到5个核心的API 、两大核心对象 向量数据库操作对象和向量数据库检索对象。
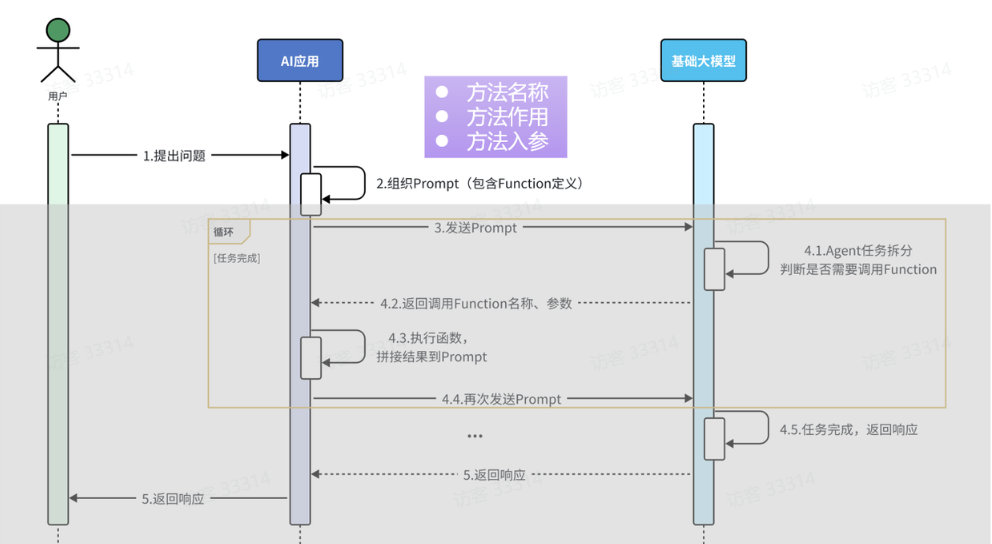
Tools工具,也就是函数调用。作用就是让ai来提供参数和函数名,请求调用我们提供好的函数,我们这边需要把函数的执行结果返回给ai,从而帮助ai更好的生成响应结果。
当用户把问题发送给AI应用,在AI应用的内部需要组织提交给大模型的数据,而这些数据中需要描述清楚我们的AI应用中有哪些函数能够被大模型调用。每一个函数的描述都包含三个部分,方法名称、方法作用、方法入参 。当AI应用把这些数据发送给大模型后,大模型会先根据用户的问题以及上下文拆解任务,从而判断是否需要调用函数,如果有函数需要调用,则把需要调用的函数的名称,以及调用时需要使用的参数准备好一并响应给AI应用。AI应用接收到响应后需要执行对应的函数,得到对应的结果,接下来把得到的结果和之前信息一块组织好再发送给大模型。
这里需要注意的是由于在一次任务的处理过程中可能需要根据顺序调用多个函数,所以当大模型接收到AI应用发送的数据继续拆解任务,如果发现还需要调用其他的函数,则会重复4.1~4.4这几个步骤,直到无需调用函数,最终把生成的结果响应该AI应用,并由AI应用发送给用户。
准备工具方法 这里我做个让ai帮用户访问数据库的小案例
引入依赖 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 <dependency > <groupId > org.mybatis.spring.boot</groupId > <artifactId > mybatis-spring-boot-starter</artifactId > <version > 3.0.3</version > </dependency > <dependency > <groupId > com.mysql</groupId > <artifactId > mysql-connector-j</artifactId > </dependency > <dependency > <groupId > org.projectlombok</groupId > <artifactId > lombok</artifactId > <scope > provided</scope > </dependency >
配置数据库连接信息 1 2 3 4 5 6 7 8 9 spring: datasource: username: root password: root url: jdbc:mysql://localhost:3306/javaweb?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true driver-class-name: com.mysql.cj.jdbc.Driver mybatis: configuration: map-underscore-to-camel-case: true
准备实体类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 @Data @NoArgsConstructor @AllArgsConstructor public class User { private Integer id; private String name; private String sex; private Integer age; private String location; private String qq; private String mail; private String user; private String password; }
准备Mapper 1 2 3 4 5 6 7 @Mapper public interface UserMapper { @Select("select * from user where id = #{id}") public User selectById (Integer id) ; @Update("update user set password = #{password} where id = #{id}") public boolean updatePwdById (Integer id, String password) ; }
准备Service 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 @Service public class UserService { @Autowired UserMapper userMapper; public User selectById (Integer id) { User user = userMapper.selectById(id); return user; } public boolean updatePwdById (Integer id, String password) { boolean b = userMapper.updatePwdById(id, password); return b; } }
准备Controller 1 2 3 4 5 @GetMapping(value = "/solve", produces = "text/html;charset=utf-8") public Flux<String> getSolve (String memoryId, String msg) { Flux<String> res = chatService.fluxSolve(memoryId, msg); return res; }
准备工具方法 LangChain4j提供了Tool注解用于对方法的作用进行描述,还有P注解用于对方法的参数进行描述,将来LangChain4j就能通过反射的方式获取到Tool注解中的作用描述、P注解中的参数描述、以及方法的名称,组织这些数据,一并发送给大模型。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 @Component public class MyTool { @Autowired UserService userService; @Tool("根据用户id查询用户信息") public User selectUserById ( @P("用户id") Integer id ) { User user = userService.selectById(id); return user; } @Tool("根据用户id直接更新密码") public boolean updateUserPwdById ( @P("用户id") Integer id, @P("密码") String password ) { boolean b = userService.updatePwdById(id, password); return b; } }
配置工具方法 在AiService注解中配置Tools工具
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 @AiService( wiringMode = AiServiceWiringMode.EXPLICIT, // chatModel = "openAiChatModel", //阻塞式模型,模型在容器中的bean名称 streamingChatModel = "openAiStreamingChatModel",//流式模型 // chatMemory = "chatMemory", //会话记忆对象 chatMemoryProvider = "chatMemoryProvider", //会话记忆对象提供者 contentRetriever = "contentRetriever", //配置向量数据库检索对象 tools = "myTool" //配置Tools工具 ) public interface ChatService { public String chat (String message) ; @UserMessage("您好,我是{{name}}, 想请教您:{{msg}}") public String chat2 (@V("name") String msg1, @V("msg") String msg2) ; @SystemMessage(fromResource = "system.txt") @UserMessage("您好,我有个问题:{{it}}") public Flux<String> fluxChat (@MemoryId String memoryId, @V("it") String msg) ; @SystemMessage("你是一个帮助用户解决问题的机器人") public Flux<String> fluxSolve (@MemoryId String memoryId, @UserMessage String msg) ; }
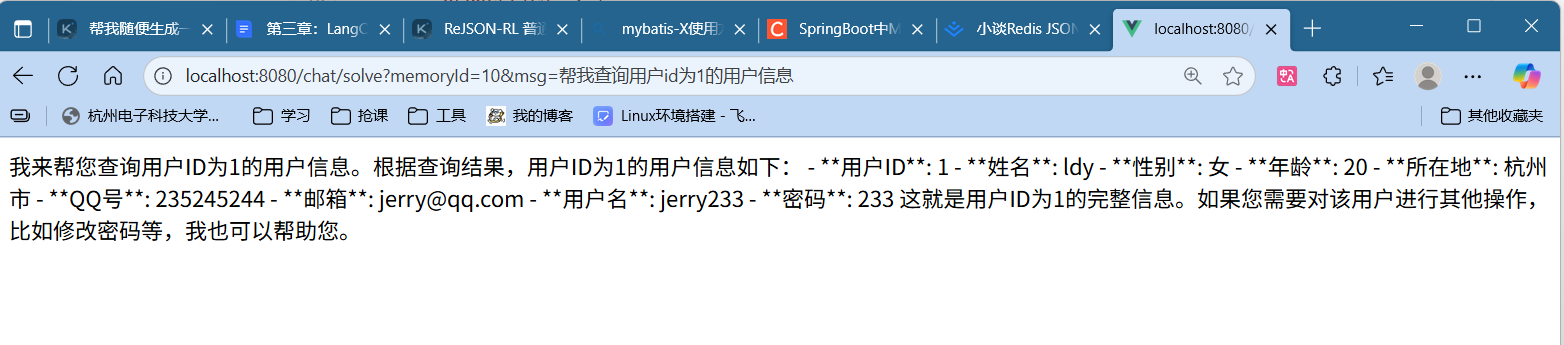
测试 查询测试
第一次请求的日志,可以看到,这里把tools的内容一并发送给ai了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 2025-08-25T16:50:54.167+08:00 INFO 27044 --- [nio-8080-exec-1] d.l.http.client.log.LoggingHttpClient : HTTP request: - method: POST - url: https://api.deepseek.com/chat/completions - headers: [Authorization: Beare...66], [User-Agent: langchain4j-openai], [Content-Type: application/json] - body: { "model" : "deepseek-chat" , "messages" : [ { "role" : "system" , "content" : "你是一个帮助用户解决问题的机器人" }, { "role" : "user" , "content" : "帮我查询用户id为1的用户信息" } ], "stream" : true , "stream_options" : { "include_usage" : true }, "tools" : [ { "type" : "function" , "function" : { "name" : "selectUserById" , "description" : "根据用户id查询用户信息" , "parameters" : { "type" : "object" , "properties" : { "id" : { "type" : "integer" , "description" : "用户id" } }, "required" : [ "id" ] } } }, { "type" : "function" , "function" : { "name" : "updateUserPwdById" , "description" : "根据用户id直接更新密码" , "parameters" : { "type" : "object" , "properties" : { "id" : { "type" : "integer" , "description" : "用户id" }, "password" : { "type" : "string" , "description" : "密码" } }, "required" : [ "id" , "password" ] } } } ] }
由下面第二次请求日志可知,ai根据用户问题,请求调用了后端的selectUserById方法。
第二次发起请求的日志,这次携带了函数调用后的结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 2025-08-25T16:51:02.509+08:00 INFO 27044 --- [hain4j-OpenAI-1] d.l.http.client.log.LoggingHttpClient : HTTP request: - method: POST - url: https://api.deepseek.com/chat/completions - headers: [Authorization: Beare...66], [User-Agent: langchain4j-openai], [Content-Type: application/json] - body: { "model" : "deepseek-chat" , "messages" : [ { "role" : "system" , "content" : "你是一个帮助用户解决问题的机器人" }, { "role" : "user" , "content" : "帮我查询用户id为1的用户信息" }, { "role" : "assistant" , "content" : "我来帮您查询用户ID为1的用户信息。" , "tool_calls" : [ { "id" : "call_0_a1448e1f-918b-4b49-9f53-d48b3229682e" , "type" : "function" , "function" : { "name" : "selectUserById" , "arguments" : "{\"id\": 1}" } } ] }, { "role" : "tool" , "tool_call_id" : "call_0_a1448e1f-918b-4b49-9f53-d48b3229682e" , "content" : "{\r\n \"id\" : 1,\r\n \"name\" : \"ldy\",\r\n \"sex\" : \"女\",\r\n \"age\" : 20,\r\n \"location\" : \"杭州市\",\r\n \"qq\" : \"235245244\",\r\n \"mail\" : \"jerry@qq.com\",\r\n \"user\" : \"jerry233\",\r\n \"password\" : \"233\"\r\n}" } ], "stream" : true , "stream_options" : { "include_usage" : true }, "tools" : [ { "type" : "function" , "function" : { "name" : "selectUserById" , "description" : "根据用户id查询用户信息" , "parameters" : { "type" : "object" , "properties" : { "id" : { "type" : "integer" , "description" : "用户id" } }, "required" : [ "id" ] } } }, { "type" : "function" , "function" : { "name" : "updateUserPwdById" , "description" : "根据用户id直接更新密码" , "parameters" : { "type" : "object" , "properties" : { "id" : { "type" : "integer" , "description" : "用户id" }, "password" : { "type" : "string" , "description" : "密码" } }, "required" : [ "id" , "password" ] } } } ] }
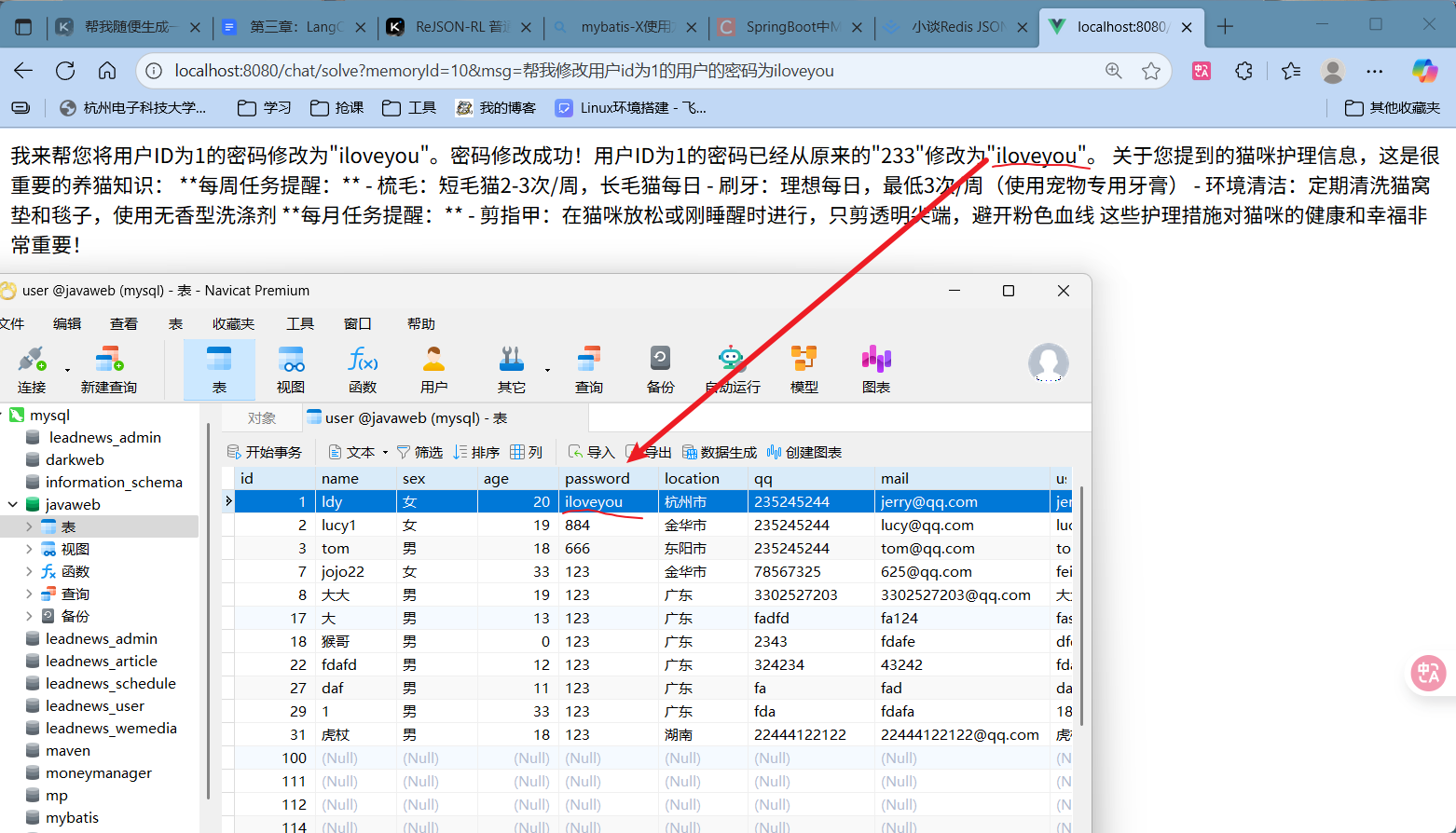
更新测试 可以看到更新也是没问题的,但问题就在于ai答非所问了后面。主要原因还是因为我余弦相似度设置的可能不够大,导致问题很偏,但还是可以命中,把rag知识库中的消息发给ai了。
总结 Tools工具的使用也是蛮简单的,只需要构建好工具方法,添加@Tool和@P注解即可。
不禁感叹,AIService这个工具类太牛,通过注解就可以整合一堆功能(流式输出、会话记忆、RAG、函数调用等功能)的实现到一个封装聊天方法的接口上面,暂时不清楚底层是如何实现的,但很牛就是了,太方便了。